is mapreduce hard to deploy and test|MapReduce: how to use it for Big Data? : distribution MapReduce excels in scalability, fault tolerance, and efficiency, making it a preferred choice for handling extensive datasets and parallel processing tasks across distributed computing nodes. Top 10 Plays | Regular Season | 2023-24 BKT EuroCup. Tip.
{plog:ftitle_list}
WEB20 de set. de 2021 · Tráiler de #ElBuenPatrón, la nueva película de Fernando León de Aranoa, protagonizada por Javier Bardem.Coproducida por The Mediapro Studio, estreno en cines.
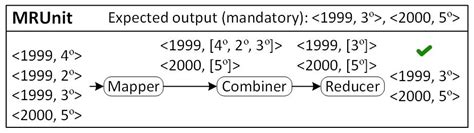
MRUnit is a testing framework that lets you test and debug Map Reduce jobs in isolation without spinning up a Hadoop cluster. In this blog post we will cover various features of MRUnit by.

I use MiniMRCluster cluster which comes with Apache. You use to start a mini Map Reduce cluster inside a unit test! HBase also has HBaseTestingUtil which is great since you . MapReduce excels in scalability, fault tolerance, and efficiency, making it a preferred choice for handling extensive datasets and parallel processing tasks across distributed computing nodes. MapReduce is a programming model for processing and generating large data sets. Users specify a Map function that processes a key/value pair to generate a set of key/value pairs, and a Reduce function that merges all . MapReduce is a parallel, distributed programming model in the Hadoop framework that can be used to access the extensive data stored in the Hadoop Distributed File .
Hadoop MapReduce jobs have a unique code architecture that raises interesting issues for test-driven development. In this article Michael Spicuzza shows how to use MRUnit to solve these.MRUnit removes as much of the Hadoop framework as possible while developing and testing. The focus is narrowed to the map and reduce code, their inputs, and expected outputs. With .
• Programming distributed systems is hard – Solution: Users write data-parallel “map” and “reduce” functions, system handles work distribution and faults The MapReduce programming model is one of the key components of the Hadoop framework. It is used to access Big Data stored within the Hadoop File System (HDFS). The significance of MapReduce is to .
MapReduce is a big data analysis model that processes data sets using a parallel algorithm on Hadoop clusters. The article explains its meaning, how it works, its features, & its applications.
MapReduce can be more cost-effective than Spark for extremely large datasets and for tasks where the speed of processing is not critical. Since MapReduce is written in Java and persists data back to disk after each map . Testing and debugging multi threaded programs is hard. Now take the same programs and massively distribute them across multiple JVMs deployed on a cluster of machines and the complexity goes off . This is configured in mapred-site.xml with yarn.app.mapreduce.am.resource.mb. How much memory will be allocated to each map or reduce operation. This should be less than the maximum size. .
Create two folders, one for the namenode directory and another for the data directory. The following are the two created folders in this example: I run Hadoop 2.2.0.2.0.6.0-101 on a local node, CentOS. My MapReduce job compiles in Eclipse when I include neccessary jars from /usr/lib/hadoop and /usr/lib/hive as dependencies in Eclipse project. Users/admins can also specify the maximum virtual memory of the launched child-task, and any sub-process it launches recursively, using mapreduce.{map|reduce}.memory.mb. Note that the value set here is a per process limit. The value for mapreduce.{map|reduce}.memory.mb should be specified in mega bytes (MB). And also the .Code examples of MapReduce. Let's take the same example with the file sample.txt and code it into a program that will perform MapReduce. For the purpose of this example, the code will be written in Java, but MapReduce programs can be written in any language. The entire MapReduce program can be fundamentally divided into three parts:
Using MRUnit to Develop and Test MapReduce Jobs. Conceptually, MapReduce jobs are relatively simple. In the map phase, each input record has a function applied to it, resulting in one or more key-value pairs. The reduce phase receives a group of the key-value pairs and performs some function over that group. As other person mentioned, depending on the Operating System and installer, the install location can be configured. For CDH4 on RHEL, using the cloudera manager as Installer, the examples and test jars can be found in the following locations. In Windows to execute and test the Map Reduce code we need to take the help of cygwin (A windows to Unix simulator). Steps to follow: 1.First install cywin. 2.set the cygpath environmental variable. now we can give local files as input to MR program. If not, you’ll want to study the Kinesis Getting Started Guide and the Elastic MapReduce documentation. To learn more about this feature, read the new Analyze Real-Time Data from Kinesis Streams chapter of the Elastic MapReduce documentation. The Elastic MapReduce FAQ has also been updated and should also be helpful. — Jeff;
Users/admins can also specify the maximum virtual memory of the launched child-task, and any sub-process it launches recursively, using mapreduce.{map|reduce}.memory.mb. Note that the value set here is a per process limit. The value for mapreduce.{map|reduce}.memory.mb should be specified in mega bytes (MB). And also the . Spark includes a comprehensive MLlib library for building and deploying machine learning models. You can use it to analyze large datasets, train models, and make predictions at scale. . Spark relies more on RAM, while MapReduce relies on hard drives. This gives MapReduce an advantage in security because if a process fails, you can continue .
Amazon EMR (Amazon Elastic MapReduce) is a web service that enables you to quickly and easily create and run clusters of Amazon Elastic Compute Cloud (EC2) instances for processing large amounts of data by running MapReduce jobs. Amazon EMR uses Hadoop, an open-source framework, to manage and process data. In this article, we’ll provide the. On other hand in Map reduce after Map and reduce tasks data will be shuffled and sorted (synchronisation barrier) and written to disk. In Spark, there is no synchronisation barrier that slows map-reduce down. And the usage of memory makes the execution engine really fast. MapReduce is the process of making a list of objects and running an operation over each object in the list (i.e., map) to either produce a new list or calculate a single value (i.e., reduce). MapReduce Analogy. Let us begin this . This post explains how to unit test a MapReduce program using MRUnit. Apache MRUnit ™ is a Java library that helps developers unit test Apache Hadoop map reduce jobs. The example used in the post looks at the Weather dataset and work with the year and temperature extracted from the data. Obviously the example can be easily translated for your .

MapReduce is capable of accepting jobs from a large number of customers. Hadoop MapReduce Master: The Hadoop MapReduce Master divides jobs into different components for better feasibility. Job-parts: They are the sub-jobs that occur as a result of the primary job’s division. Clients submit jobs to the MapReduce Master in the MapReduce .
What Is MapReduce? Meaning, Working, Features,
Test drives and other trials; And many more exclusive benefits; Sign into your account Create an account. . Deploy and manage resources across your private and public clouds while retaining control of your data and flexibility over how you consume and manage your services. . MapReduce can scale across thousands of nodes, most likely due to . Hadoop MapReduce jobs have a unique code architecture that raises interesting issues for test-driven development. In this article Michael Spicuzza provides a real-world example using MRUnit .
The Genesis of Datacenter Computing: Map Reduce A MapReduce framework (or system) is usually composed of three oper ations (or steps): 1. Map: each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one cop y of the redundant input data is processed. 2. Introduction. MapReduce is a processing module in the Apache Hadoop project. Hadoop is a platform built to tackle big data using a network of computers to store and process data.. What is so attractive about Hadoop is that affordable dedicated servers are enough to run a cluster. You can use low-cost consumer hardware to handle your data. Continuous MapReduce works in much the same way as regular MapReduce, only without ever exiting. The main differences are the addition of a key extraction phase, and that the order of operations is a little different to facilitate the continuous, streaming execution. In normal MapReduce, the map function emits arbitrary key-value pairs.
sudo pip install mrjob. Run the following command to start our MapReduce quest: python mapr.py -r emr shakespeare.txt --conf-path mrjob.conf. Sit back and wait for its completion. Once it's finished, it generates an output file in a temperory dictionary in our S3 storage.
Learning Objectives • describe the role mappers and reducers have in MapReduce jobs • describe Spark concepts related to data lineage (RDDs, operations, transformations, actions) • deploy Spark with multiple workers • write Spark code using RDD and DataFrame APIs TeraSort Benchmark is used to test both, MapReduce and HDFS by sorting some amount of data as quickly as possible in order to measure the capabilities of distributing and mapreducing files in cluster. In an earlier post we looked into debugging a MapReduce in Eclipse and here we looked at unit testing Hadoop R Streaming programs. In this blog entry, we will look into how to unit test MapReduce programs using Apache MRUnit. In either case there is no need start HDFS and MR related daemons.
pastel uv analyzer
Resultado da Os Mapas Mentais são para você que: Quer aumentar seu conhecimento bíblico. Deseja ENTENDER o que a Palavra de Deus quer dizer. Quer .
is mapreduce hard to deploy and test|MapReduce: how to use it for Big Data?